引き続きOpenSearchのQueryDSLについてちょっと詳しく見ていくことにします。
まずはどのような検索方法が存在するのか確認してきます。
QueryDSLについは以下のページを参考にしました。
https://opensearch.org/docs/latest/query-dsl/
コンテキストのクエリとフィルター処理
クエリコンテキスト
クエリコンテキストは「ドキュメントはクエリ句とどの程度一致しているか」ということを指定する。どの程度一致しているか、については関連性スコアが計算され、スコアが高いほど関連性が強いと推定されます。
GET shakespeare/_search
{
"query": {
"match": {
"text_entry": "long live king"
}
}
}フィルタコンテキスト
フィルターコンテキストは関連性スコアは計算せず、一致するドキュメントを返却します。数値で比較したい場合やtrue/falseのようなbool値を計算するのに良さそうでした。
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "honors": true }},
{ "range": { "graduation_year": { "gte": 2020, "lte": 2022 }}}
]
}
}
}用語レベルのクエリと全文クエリ
用語レベルのクエリ
構造化データの検索に対して利用されるクエリ
GET shakespeare/_search
{
"query": {
"term": {
"text_entry": "To be, or not to be"
}
}
}上記は用語クエリを利用したサンプル。
「To be, or not to be」という用語が、テキスト フィールドの分析された値のみが格納されている逆インデックスで文字どおりに検索されるためです。用語レベルのクエリは、予期しない結果をもたらすことが多いため、分析されたテキスト フィールドの検索には適していません。
https://opensearch.org/docs/latest/query-dsl/term-vs-full-text/
とのことで、検索クエリに分析を行わず、そのまま検索する場合は「keyword」を利用するのが良いとのこと。
全文クエリ
全文検索に利用されるクエリ
GET shakespeare/_search
{
"query": {
"match": {
"text_entry": "To be, or not to be"
}
}
}上記は全文検索のサンプル
text_entry検索クエリ「To be, or not to be」は分析され、ドキュメントのフィールドと同様にトークンの配列にトークン化されます。全文クエリは、検索クエリとtext_entryすべてのドキュメントのフィールドの間のトークンの共通部分を取得し、関連性スコアで結果を並べ替えます。
https://opensearch.org/docs/latest/query-dsl/term-vs-full-text/
とのことで、用語レベルのクエリ、全文検索クエリで使い分けに注意する必要がありそうですね。
用語レベルのクエリには何があるのか
用語レベルのクエリ一覧はこちら
https://opensearch.org/docs/latest/query-dsl/term/
wildcardやregexを利用した検索は用語レベルのクエリに分類されるようですね
全文検索クエリには何があるのか
全文検索クエリの一覧はこちら
https://opensearch.org/docs/latest/query-dsl/full-text/
machやmatch_allなどはこちらに分類されるようです。
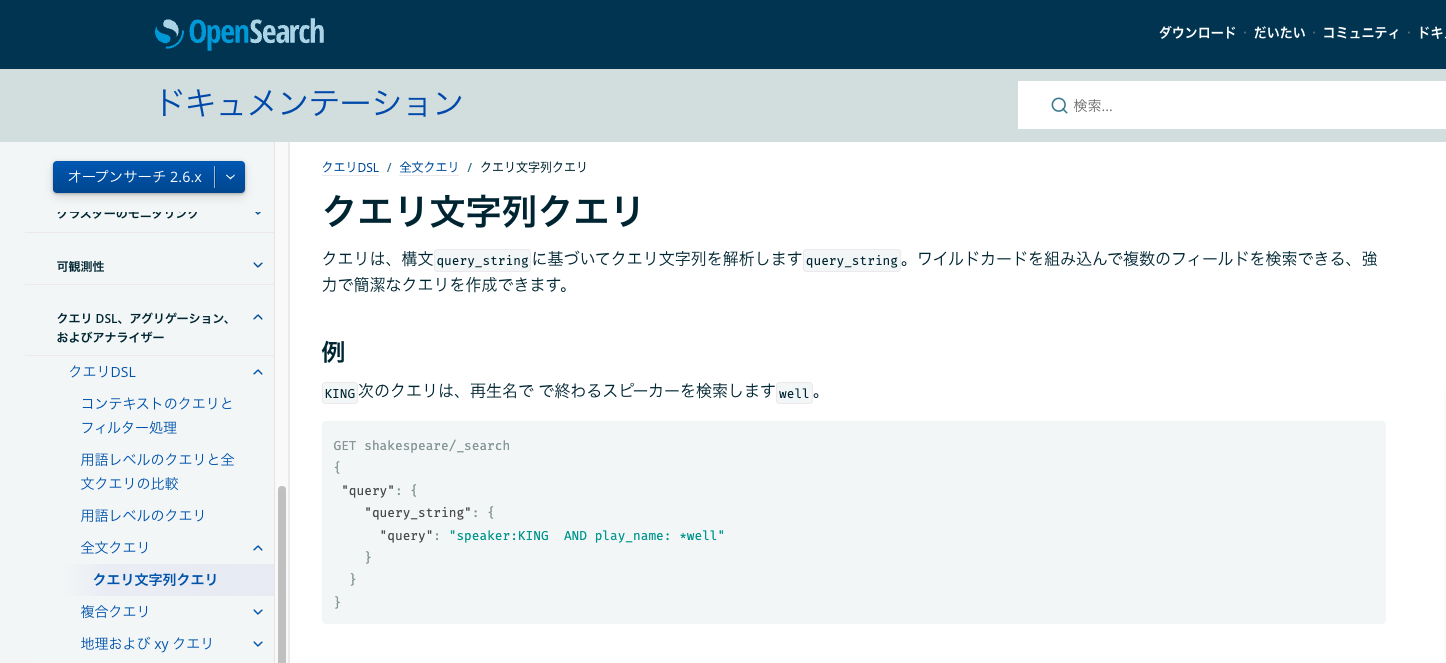
クエリ文字列
全文クエリの「query_string」を利用する場合、クエリ文字列が利用できるとのこと。
クエリ文字列についてはこちら
https://opensearch.org/docs/latest/query-dsl/full-text/query-string/
説明を読むとGETパラメータを利用してクエリを組み立てるときに利用できそうな感じでした。
なんとなく、Solrの検索クエリと似た仕組みに見えました。
以上
ということで、OpenSearchのQueryDSLを詳しく見てみるのお話でした。
QueryDSLは他にも話題が残ってますので、しばらくはドキュメントを読み解く話を載せていこうと思います。