
またまたStable Diffusionネタです。ドはまりしたので、しばらくはこの話題になりそうです
ファインチューニングとは?
ファインチューニング(転移学習)とは以下のようなものになります。
一般的な手法である『教師あり学習』は、あらかじめ正解を与えて学習を行うフローとなっています。しかし正解を導くために大量のデータが必要となり、かつ学習時間も膨大にかかるのが難点です。
一方で転移学習は、タスクの仮説立てを行ううえで、別のタスクですでに学習された知識を転用し、仮説立てを行わせる手法となります。大量のデータと学習にかかる時間を大幅に削減できるため、非常に効率的な手法として評価されています。
転移学習とは?ファインチューニングとの違いや活用例をご紹介 – 顧問、専門家などのプロ人材紹介サービス (hipro-job.jp)
Stable Diffusionの場合、汎用的なイラスト生成モデル故、特定の分野のイラストを生成しようとした場合、なかなかうまくいかないことがあります。具体的にはアニメ系のイラスト生成ですね。
ファインチューニングを行うことで、高度なイラストを生成できる特徴を生かしつつ、アニメ系に特化したモデルも作成できるのではと思い、実験してみることにしました。
すでに実施されている方のブログでは、「いらすとや」でファインチューニングを行い、結果を表示していました。
サービス閉鎖してしまった「mimic」も、おそらく同じ技術を利用してイラストを生成していると思われます。
早速やってみる
環境は以下の通りです
・OS:Windows11
・ CPU:Corei7 9700K
・GPU:RTX2080 VRAM 8GB
可能であればLinux環境で動かすことを推奨します
このスクリプトにはUnix環境でしか利用できないパッケージが利用されており、トラブルシューティングやエラー修正で精神を削がれます
また、いろいろとプログラム修正をしないと動かなかったので、先にページ下部のエラー集を見ておくとよいかもしれません
それでもWindowsで動かしたいという方はお進みください。
・・・
redditの投稿にやり方が書いてあるため、それに従って進めていきます
https://www.reddit.com/r/StableDiffusion/comments/wvzr7s/tutorial_fine_tuning_stable_diffusion_using_only/
環境構築
指定のリポジトリをローカルにクローンします。クローン後、フォルダ移動し、condaコマンドで環境を構築します
Windows環境にAnaconda、Git がインストールされていることが前提なので、インストールされていない場合過去記事も参照してください
git clone https://github.com/rinongal/textual_inversion.git
cd textual_inversion
# conda remove -n ldm --all # すでにldmの仮想環境が存在する場合、いったん削除する
conda env create -f environment.yaml
conda activate ldm
pip install -e .学習用画像の準備
手順によれば「512px × 512pxの画像5枚が必要」とのことでした。
今回はmimicクローズベータに参加されていた「たんたんめん」さんの画像を利用させていただき、学習することにしました。
かわいいイラストが多くて、学習用画像を選定するのに時間を取られてしまいました・・・
学習用画像は、ひとまず顔の部分のみ512 × 512の大きさに切りだして準備しました
画像はGimpを使ってトリミングを行い、5枚の学習用画像を作成しました。
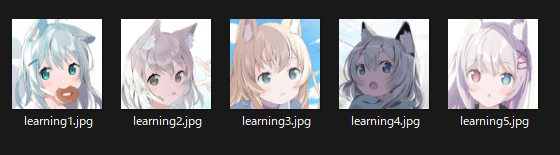
お察しの通り、ケモミミ好きです・・・
トレーニングの実施
トレーニングコマンドを実施する前に、準備をします
・準備1:Stable Diffusionモデルの準備
StableDiffusion V1.4のモデルが必要です。HuggingFaceからダウンロードしてもよいですし、Stable Diffusionの環境が構築済みであれば、コピーして適当なフォルダに保存しておきます。
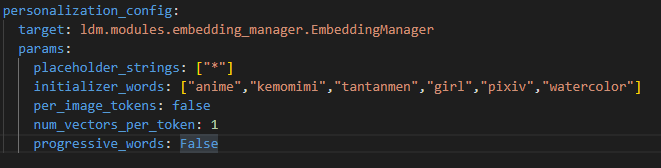
・準備2:initializer_words の準備
configs/stable-diffusion/v1-finetune.yaml をテキストエディタなどで開き、initializer_wordsの設定部分を探します。
このパラメータは重要で、トレーニング内容を説明する簡単な語句の羅列を指定するようで、複数指定する場合は2重引用符で囲み、カンマで区切るようです。今回は以下の画像のように指定してみました
準備ができたので、トレーニングを行います
以下のコマンドで実施してみました
python main.py --base configs/stable-diffusion/v1-finetune.yaml -t --actual_resume ./models/ldm/stable-diffusion-v1/sd-v1-4.ckpt -n tantanmen_train --gpus 1, --data_root ./LerningImages/512使ってみる
以上で新しい特徴を覚えたモデルが生成されたはずなので、実際に実行してみます
python scripts/stable_txt2img.py --ddim_eta 0.0 --n_samples 1 --n_iter 2 --scale 10.0 --ddim_steps 50 --embedding_path ./logs/5122022-09-05T08-03-26_tantanmen_train/checkpoints/embeddings.pt --ckpt ./models/ldm/stable-diffusion-v1/sd-v1-4.ckpt --config ./logs/5122022-09-05T08-03-26_tantanmen_train/configs/5122022-09-05T08-03-26-project.yaml --prompt "anime, girl, japanese, *"パラメータは各個人の環境でファイル名が異なってくるので、そのあたりはご注意ください。
GPUメモリ不足で、n_samplesに2以上の値を入力するとメモリ不足で落ちました・・・
n_samples=1で実行することで、ひとまずイラストは生成されました。
生成されたイラスト

素のStable Diffusionで生成するよりもまともな(比較的かわいい)結果が出力されるけど、入力画像には程遠い画像が出力された
が、ひとまず今回の結論。
パラメータなどいじれれば、また結果は変わるかもしれないけど、VRAM8GBではいろいろ限界なんです・・・
オプティマイズ版が出るか、つよつよGPUを持っている方がいろいろ実験されるのを待つことにします・・・
追伸
mimicって、ちゃんと学習画像に近い画像を生成できていたので、割と高度なことをやってるんだなぁと思った
エラー集
Traceback (most recent call last):
File "main.py", line 762, in <module>
ngpu = len(lightning_config.trainer.gpus.strip(",").split(','))
AttributeError: 'int' object has no attribute 'strip'
main.py 762行目あたりでngpuに必ず1を代入するように修正して回避
if not cpu:
# ngpu = len(lightning_config.trainer.gpus.strip(",").split(','))
ngpu = 1
else:
ngpu = 1Traceback (most recent call last):
File "main.py", line 800, in <module>
signal.signal(signal.SIGUSR1, melk)
AttributeError: module 'signal' has no attribute 'SIGUSR1'
main.py 800行目あたりのsignal処理一式を変更
import signal
signal.signal(signal.SIGTERM, melk)
signal.signal(signal.SIGTERM, divein)Traceback (most recent call last):
File "main.py", line 806, in <module>
trainer.fit(model, data)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 740, in fit
self._call_and_handle_interrupt(
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 685, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 777, in _fit_impl
self._run(model, ckpt_path=ckpt_path)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1199, in _run
self._dispatch()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1279, in _dispatch
self.training_type_plugin.start_training(self)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\plugins\training_type\training_type_plugin.py", line 202, in start_training
self._results = trainer.run_stage()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1289, in run_stage
return self._run_train()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1311, in _run_train
self._run_sanity_check(self.lightning_module)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1375, in _run_sanity_check
self._evaluation_loop.run()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\base.py", line 145, in run self.advance(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\dataloader\evaluation_loop.py", line 110, in advance
dl_outputs = self.epoch_loop.run(dataloader, dataloader_idx, dl_max_batches, self.num_dataloaders)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\base.py", line 145, in run self.advance(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\epoch\evaluation_epoch_loop.py", line 122, in advance
output = self._evaluation_step(batch, batch_idx, dataloader_idx)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\epoch\evaluation_epoch_loop.py", line 217, in _evaluation_step
output = self.trainer.accelerator.validation_step(step_kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\accelerators\accelerator.py", line 236, in validation_step
return self.training_type_plugin.validation_step(*step_kwargs.values())
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\plugins\training_type\training_type_plugin.py", line 219, in validation_step
return self.model.validation_step(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\autograd\grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 368, in validation_step
_, loss_dict_no_ema = self.shared_step(batch)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 907, in shared_step
loss = self(x, c)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 915, in forward
c = self.get_learned_conditioning(c)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 594, in get_learned_conditioning c = self.cond_stage_model.encode(c, embedding_manager=self.embedding_manager)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\encoders\modules.py", line 324, in encode
return self(text, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\encoders\modules.py", line 319, in forward
z = self.transformer(input_ids=tokens, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\encoders\modules.py", line 297, in transformer_forward
return self.text_model(
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\encoders\modules.py", line 258, in text_encoder_forward
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids, embedding_manager=embedding_manager) File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\encoders\modules.py", line 180, in embedding_forward
inputs_embeds = self.token_embedding(input_ids)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\sparse.py", line 158, in forward
return F.embedding(
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\functional.py", line 2044, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument index in method wrapper__index_select)
パラメータを「–gpus 0, → –gpus 1,」に変更したらひとまずエラーは消えました
こちらは各々の環境で指定する番号が異なるようですので、gpu 0, → gpu 1, というように0番からしていてうまく動く番号を探るのがよさそうです
Traceback (most recent call last):
File "main.py", line 806, in <module>
trainer.fit(model, data)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 740, in fit
self._call_and_handle_interrupt(
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 685, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 777, in _fit_impl
self._run(model, ckpt_path=ckpt_path)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1137, in _run
self.accelerator.setup_environment()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\accelerators\gpu.py", line 39, in setup_environment
super().setup_environment()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\accelerators\accelerator.py", line 83, in setup_environment
self.training_type_plugin.setup_environment()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\plugins\training_type\ddp.py", line 185, in setup_environment
self.setup_distributed()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\plugins\training_type\ddp.py", line 272, in setup_distributed
init_dist_connection(self.cluster_environment, self.torch_distributed_backend)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\utilities\distributed.py", line 387, in init_dist_connection
torch.distributed.init_process_group(
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\distributed\distributed_c10d.py", line 583, in init_process_group
default_pg = _new_process_group_helper(
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\distributed\distributed_c10d.py", line 708, in _new_process_group_helper
raise RuntimeError("Distributed package doesn't have NCCL " "built in")
RuntimeError: Distributed package doesn't have NCCL built in
こちらの記事を参考に、main.pyを以下のように修正
if __name__ == "__main__":
# custom parser to specify config files, train, test and debug mode,
# postfix, resume.
# `--key value` arguments are interpreted as arguments to the trainer.
# `nested.key=value` arguments are interpreted as config parameters.
# configs are merged from left-to-right followed by command line parameters.
・・・省略・・・
os.environ["PL_TORCH_DISTRIBUTED_BACKEND"] = "gloo" ←これを追加
now = datetime.datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
# add cwd for convenience and to make classes in this file available when
# running as `python main.py`
# (in particular `main.DataModuleFromConfig`)Traceback (most recent call last):
File "main.py", line 808, in <module>
trainer.fit(model, data)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 740, in fit
self._call_and_handle_interrupt(
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 685, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 777, in _fit_impl
self._run(model, ckpt_path=ckpt_path)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1199, in _run
self._dispatch()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1279, in _dispatch
self.training_type_plugin.start_training(self)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\plugins\training_type\training_type_plugin.py", line 202, in start_training
self._results = trainer.run_stage()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1289, in run_stage
return self._run_train()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1319, in _run_train
self.fit_loop.run()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\base.py", line 145, in run
self.advance(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\fit_loop.py", line 234, in advance
self.epoch_loop.run(data_fetcher)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\base.py", line 145, in run
self.advance(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\epoch\training_epoch_loop.py", line 193, in advance
batch_output = self.batch_loop.run(batch, batch_idx)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\base.py", line 145, in run
self.advance(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\batch\training_batch_loop.py", line 88, in advance
outputs = self.optimizer_loop.run(split_batch, optimizers, batch_idx)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\base.py", line 145, in run
self.advance(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\optimization\optimizer_loop.py", line 215, in advance
result = self._run_optimization(
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\optimization\optimizer_loop.py", line 266, in _run_optimization
self._optimizer_step(optimizer, opt_idx, batch_idx, closure)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\optimization\optimizer_loop.py", line 378, in _optimizer_step
lightning_module.optimizer_step(
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\core\lightning.py", line 1652, in optimizer_step
optimizer.step(closure=optimizer_closure)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\core\optimizer.py", line 164, in step
trainer.accelerator.optimizer_step(self._optimizer, self._optimizer_idx, closure, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\accelerators\accelerator.py", line 336, in optimizer_step
self.precision_plugin.optimizer_step(model, optimizer, opt_idx, closure, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\plugins\precision\precision_plugin.py", line 163, in optimizer_step
optimizer.step(closure=closure, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\optim\optimizer.py", line 88, in wrapper
return func(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\autograd\grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\optim\adamw.py", line 92, in step
loss = closure()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\plugins\precision\precision_plugin.py", line 148, in _wrap_closure
closure_result = closure()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\optimization\optimizer_loop.py", line 160, in __call__
self._result = self.closure(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\optimization\optimizer_loop.py", line 142, in closure
step_output = self._step_fn()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\optimization\optimizer_loop.py", line 435, in _training_step
training_step_output = self.trainer.accelerator.training_step(step_kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\accelerators\accelerator.py", line 216, in training_step
return self.training_type_plugin.training_step(*step_kwargs.values())
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\plugins\training_type\ddp.py", line 439, in training_step
return self.model(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\parallel\distributed.py", line 886, in forward
output = self.module(*inputs[0], **kwargs[0])
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\overrides\base.py", line 81, in forward
output = self.module.training_step(*inputs, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 352, in training_step
loss, loss_dict = self.shared_step(batch)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 907, in shared_step
loss = self(x, c)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 920, in forward
return self.p_losses(x, c, t, *args, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 1056, in p_losses
model_output = self.apply_model(x_noisy, t, cond)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 1028, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 1513, in forward
out = self.diffusion_model(x, t, context=cc)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\diffusionmodules\openaimodel.py", line 732, in forward
h = module(h, emb, context)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\diffusionmodules\openaimodel.py", line 85, in forward
x = layer(x, context)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\attention.py", line 258, in forward
x = block(x, context=context)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\attention.py", line 209, in forward
return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\diffusionmodules\util.py", line 116, in checkpoint
return func(*inputs)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\attention.py", line 213, in _forward
x = self.attn2(self.norm2(x), context=context) + x
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\modules\attention.py", line 175, in forward
k = self.to_k(context)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\modules\linear.py", line 103, in forward
return F.linear(input, self.weight, self.bias)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\nn\functional.py", line 1848, in linear
return torch._C._nn.linear(input, weight, bias)
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 8.00 GiB total capacity; 7.20 GiB already allocated; 0 bytes free; 7.29 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
で書かれている情報とtwitterを参考に以下のように修正
修正対象は「config/stable-diffusion/v1-finetune.yaml」です
data:
target: main.DataModuleFromConfig
params:
batch_size: 1 # 2
num_workers: 1 # 2
wrap: false
train:
target: ldm.data.personalized.PersonalizedBase
params:
size: 256 # 512
set: train
per_image_tokens: false
repeats: 100
validation:
target: ldm.data.personalized.PersonalizedBase
params:
size: 256 # 512
set: val
per_image_tokens: false
repeats: 10機械学習の分野ではVRAM 8GはよわよわGPUの部類に入るのか・・・
Traceback (most recent call last):
File "main.py", line 810, in <module>
trainer.fit(model, data)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 740, in fit
self._call_and_handle_interrupt(
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 685, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 777, in _fit_impl
self._run(model, ckpt_path=ckpt_path)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1199, in _run
self._dispatch()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1279, in _dispatch
self.training_type_plugin.start_training(self)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\plugins\training_type\training_type_plugin.py", line 202, in start_training
self._results = trainer.run_stage()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1289, in run_stage
return self._run_train()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1319, in _run_train
self.fit_loop.run()
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\base.py", line 145, in run
self.advance(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\fit_loop.py", line 234, in advance
self.epoch_loop.run(data_fetcher)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\base.py", line 145, in run
self.advance(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\loops\epoch\training_epoch_loop.py", line 216, in advance
self.trainer.call_hook("on_train_batch_end", batch_end_outputs, batch, batch_idx, **extra_kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1495, in call_hook
callback_fx(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\callback_hook.py", line 179, in on_train_batch_end
callback.on_train_batch_end(self, self.lightning_module, outputs, batch, batch_idx, 0)
File "F:\Project\MachineLerning\textual_inversion\main.py", line 436, in on_train_batch_end
self.log_img(pl_module, batch, batch_idx, split="train")
File "F:\Project\MachineLerning\textual_inversion\main.py", line 404, in log_img
images = pl_module.log_images(batch, split=split, **self.log_images_kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\torch\autograd\grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "F:\Project\MachineLerning\textual_inversion\ldm\models\diffusion\ddpm.py", line 1320, in log_images
xc = log_txt_as_img((x.shape[2], x.shape[3]), batch["caption"])
File "F:\Project\MachineLerning\textual_inversion\ldm\util.py", line 25, in log_txt_as_img
font = ImageFont.truetype('data/DejaVuSans.ttf', size=size)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\PIL\ImageFont.py", line 844, in truetype
return freetype(font)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\PIL\ImageFont.py", line 841, in freetype
return FreeTypeFont(font, size, index, encoding, layout_engine)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\PIL\ImageFont.py", line 193, in __init__
self.font = core.getfont(
OSError: cannot open resource
DejaVuSans.ttfというフォントが必要らしいので、GitHubからダウンロードして
「ldm/data/」に格納しました
そして、以下のソースも修正しました
textual_inversion/ldm/util.py
# 「import os」をファイル先頭のimportが記述されている部分に追加します
from inspect import isfunction
from PIL import Image, ImageDraw, ImageFont
import os # ←こちらを追記
#以下のメソッドでダウンロードしたフォントの読み込みパスを修正します
def log_txt_as_img(wh, xc, size=10):
# wh a tuple of (width, height)
# xc a list of captions to plot
b = len(xc)
txts = list()
for bi in range(b):
txt = Image.new("RGB", wh, color="white")
draw = ImageDraw.Draw(txt)
# font = ImageFont.truetype('data/DejaVuSans.ttf', size=size)
print(os.getcwd() + '/ldm/data/DejaVuSans.ttf')
font = ImageFont.truetype(os.getcwd() + '/ldm/data/DejaVuSans.ttf', size=size)
・・・以下修正なしTraceback (most recent call last):
File "main.py", line 815, in <module>
trainer.test(model, data)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 911, in test
return self._call_and_handle_interrupt(self._test_impl, model, dataloaders, ckpt_path, verbose, datamodule)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 685, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 954, in _test_impl
results = self._run(model, ckpt_path=self.tested_ckpt_path)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\trainer.py", line 1128, in _run
verify_loop_configurations(self)
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\configuration_validator.py", line 42, in verify_loop_configurations
__verify_eval_loop_configuration(trainer, model, "test")
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\pytorch_lightning\trainer\configuration_validator.py", line 186, in __verify_eval_loop_configuration
raise MisconfigurationException(f"No `{loader_name}()` method defined to run `Trainer.{trainer_method}`.")
pytorch_lightning.utilities.exceptions.MisconfigurationException: No `test_dataloader()` method defined to run `Trainer.test`.
直し方がわからないのでテスト実行部分を削除しました・・・
main.pyの814行目あたりを以下のようにコメントアウト
main.py
# if not opt.no_test and not trainer.interrupted:
# trainer.test(model, data)(ldm) PS F:\Project\MachineLerning\stable-diffusion-optimize> python scripts/txt2img.py --ddim_eta 0.0 --n_samples 8 --n_iter 2 --scale 10.0 --ddim_steps 50 --embedding_path ./logs/5122022-09-04T22-55-01_tantanmen_train/checkpoints/embeddings_gs-6099.pt --ckpt_path ./models/ldm/text2img-large/model.ckpt --prompt "a photo of *"
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS]
[--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA] [--n_iter N_ITER] [--H H] [--W W]
[--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE]
[--config CONFIG] [--ckpt CKPT] [--seed SEED] [--precision {full,autocast}]
txt2img.py: error: unrecognized arguments: --embedding_path ./logs/5122022-09-04T22-55-01_tantanmen_train/checkpoints/embeddings_gs-6099.pt --ckpt_path ./models/ldm/text2img-large/model.ckpt
GitHubに書かれているコマンドが間違えている・・・
パラメータを「–ckpt_path」→「–ckpt」に修正
Traceback (most recent call last):
File "scripts/stable_txt2img.py", line 287, in <module>
main()
File "scripts/stable_txt2img.py", line 277, in main
Image.fromarray(grid.astype(np.uint8)).save(os.path.join(outpath, f'{prompt.replace(" ", "-")}-{grid_count:04}.jpg'))
File "F:\Project\MachineLerning\Anaconda\envs\ldm\lib\site-packages\PIL\Image.py", line 2209, in save
fp = builtins.open(filename, "w+b")
OSError: [Errno 22] Invalid argument: 'outputs/txt2img-samples\\anime,-girl,-japanese,-*-0000.jpg'
scripts/stable_txt2img.py
277行目あたりを以下のように修正
# to image
grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
prompt = prompt.replace("*", "-")
Image.fromarray(grid.astype(np.uint8)).save(os.path.join(outpath, f'{prompt.replace(" ", "-")}-{grid_count:04}.jpg'))
grid_count += 1今回のファインチューニングを利用するには、promptに * を入れる必要がある
ファイル名はpromptから生成される
Windowsではファイル名に * が利用できない
という流れでエラーになるので、*を無害な文字に変換してファイル名を生成します



ありがとうございます。参考にしてwindows環境で動かすことが出来ました。
コメントありがとうございます。
自分以外の環境でも無事に動いたとのことで、安心しました。
詳細に解説して下さったおかげでちゃんと動作しました。
ありがとうございます。
念のため、textual_inversion/ldm/util.pyに「import os」を追加する記述を追加して下さりますと、後続の方により親切かもしれません!
また、自環境では、実行時のコマンドを「–gpus 0」と指定しないと動きませんでした。僕の環境次第かもしれませんがご参考までに。僕の環境はwindows10+RTX3090の1枚刺しです。
コメントありがとうございます。
ご指摘の通り。「import os」の記述が抜けておりましたので、追記いたしました。
gpusのパラメータについてもご連絡ありがとうございました。
念のため「gpus 0」で動かしたみましたが、やはり自分の環境ではエラーなってしまいました。
こちらは「各々の環境でパラメータが異なります」ということで、記述内容を修正しました。