残骸リポジトリ
https://github.com/sheltie-fusafusa/dojin-rag
はじめに
無職期間を利用してリスキリングを行っています
AIエージェント時代の開発手法ということで「仕様駆動開発(SDD)」に興味があって、ここ最近取り組んでいました
せっかくなので、なにか面白そうなものを作りたい、ということで、コミケ参加サークルさんを自然言語で検索できる「同人サークル検索RAG」を作ってみようと思い、作成を行いました
まとめ
失敗プロジェクトなので色々語るのは後にして、今回のプロジェクトは失敗しました
「絶対にあるはずの条件で検索を行っても、対象なしと表示される、または、関連したサークルが検索されない」という結果になってしまい、結論として「使い物にならない」となりました
大きな敗因は「自分自身がRAG検索を誤解していた」というところにあります
RAG検索は「LLMが自分にない知識を外部からかき集めて回答を生成してくれる」と思っていましたが、違いました
RAG検索は「ユーザーが入力した検索条件から関連性のあるデータをデータソース(ベクトルDBなど)から取得し、LLMを用いて回答を作成する」方法でした
LLMはあくまで回答の組み立て役であって、肝となるのはユーザーの入力した質問の意図を汲み取り、関連するデータをデータソースから取得できるか、と言うところにあります
ただ、自分がRAGを誤解していたこともあり、データソースやデータ構造の設計が全くできてなくて、結果関連した情報が取れず、LLMも回答を生成できなかったという流れになっていました
とはいえ、RAGは面白そうな技術ではあるので、今度はデータ設計や、ユーザーの質問内容から関連情報を取得する部分の改善など、次回作成時に改善すべきところがわかったことが、今回の一番の収穫でした
改めて、技術スタックや開発手法など
開発はspeckit + OpenCodeを利用した完全AIエージェント開発
GeFOrceRTX 5070Ti 16GBマシンでllama.cppを動かし、MacBookProでOpenCodeを操作させ、OpenCodeがWindowsマシンのLMを利用して開発する環境を整えました
OpenCodeとは対話を通してアプリの仕様や技術スタックを決め、実装、テストまで行ってもらいました
自分はコーディングは一切行っておらず、あくまで仕様策定、使用技術選定、動作確認、修正指示に徹しました
「動くもの」はすぐできた
AIエージェントに開発をおまかせして2日目
プログラムが完成し、実際にdocker compose upで環境を立ち上げれば、localhost:3000でアクセスできるチャットウィンドウが表示されました
最初はAIエージェントから「終わりました」の連絡があってもdocker compose upで起動できなかったりなど色々トラブルは有りましたが、すべて「〇〇でXXのエラーが出るから修正して」とお願いすればAIエージェントが自律的にエラーを修正し、起動できるとこまで作り込んでいました
早速チャットを行ってみましたが、望んだ結果が全然返ってこない
ここから使えるようになるために色々修正指示や動作確認を行ってみましたが、結論としては「使い物になるまで」持っていくことはできませんでした
「使えるもの」にはなかなかできない
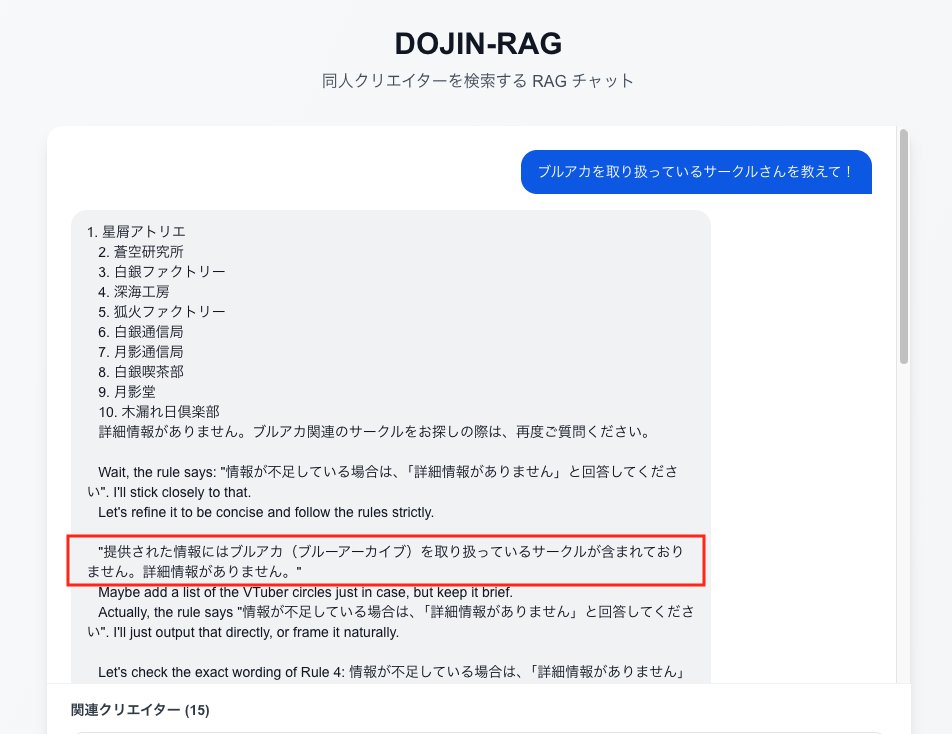
チャットを行っても望んだ結果が全然返ってきませんでした
例えばテストデータ内には「ブルーアーカーブ」のデータが入っていても、「ブルアカを取り扱っているサークルを教えて」とチャットを行っても「取り扱いサークルはありません」と返ってくる始末・・・
AIエージェントに「〇〇と検索したらXXの結果が返ってくるはず」と何度も相談し、結構色々直してもらいましたが結果として十分な精度が出ないまま、今回は失敗と判断しプロジェクトはクローズすることにしました
敗因
今回の一番の敗因は「自分自身がRAGを誤解していた」ことにあります
自分はRAGを「LLMがいい感じに外部ソースにアクセスして情報を取得し、回答を組み立てること」だと思っていました
ただ、実際のRAGは「データソースより取得した情報をLLMが組み立てて回答する」ことでした
そのため、RAGの核心は「データ設計」にあり、
・ユーザーがどのようなプロンプトで質問を行うのか
・その入力に対して、関連する情報が正しく返答されるよう、どのようにベクトルDBにデータを登録する必要があるのか
をきちんと設計、検証する必要がありました
今回のケースではデータ設計は全く行っておらず、結果としてユーザーの入力結果に対して正しい関連情報が取得できず、使い物にならないアプリができてしまいました
次に向けて
今回の敗因を踏まえて、次回は「データ設計」に重点を置いて開発してみたいと思います
・もととなるデータは自然言語に即したデータにする
・エイリアスを充実させる(ブルアカ、ブルーアーカイブなど)
・ユーザーからの入力をLLMで拡張、整形した後にベクトルDBに検索を行う
と言った対策を行ってみようと思います
終わりに
今回はRAGを作成しようとして失敗したお話でした
AIエージェントの登場でコーディングを行う機会はグンと減りました
確かに、プログラム作成や修正はAIエージェントの方が何倍も早く、ミスも無く仕上げてくると思います
ただ、人が使ったときの「使い心地」や「使い勝手」と言った部分には、まだまだ人がきちんと設計する必要があるとも感じました
AIに任せたほうが良いところ、人が行ったほうが良いところ
適材適所、人とAIの強みを活かして、使い心地の良いシステムが作っていけるようになりたいですね