タイトルのとおりです
ローカルLLMをAntigravityのコーディングエージェントとして利用したい
GoogleのAntigravityを利用して主にプログラミングを行っているのですが、平日/休日に利用していると前モデルでトークンの上限にぶつかってしまいコーディング支援が受けられなくなることがしばしばありました。
そこで、そこそこ強いゲーミングPCにOllamaをセットアップして自宅ではそちらを利用することでトークンを節約することにしました
概要
今回は
・WindowsPC:Ollamaサーバー(LLMモデルを動かすためのサーバー)
・MacBookPro:クライアント(WindowsPCからコーディング支援を受ける)
という構成になっています
まずはWindowsPCにOllamaを導入し、LLMモデルが動くようにセットアップします
WindowsPC側のセットアップ
まずはOllamaをインストールします
ダウンロードページからインストールするマシンに適したバイナリを入手できます
https://ollama.com/download
下記コマンドはWindowsの例です
irm https://ollama.com/install.ps1 | iexollamaが起動していればデフォルトでAPIサーバーとして起動しているため、ブラウザにlocalhostでアクセスすることで動作しているか確認することができます
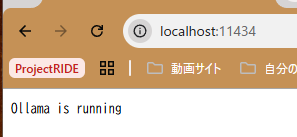
無事に動作確認が取れたら、利用したいモデルをOllamaに導入します
モデルはHugging Faceで大量に見つかると思います
※Ollamaを使用する場合、.gguf形式のファイルが利用できます
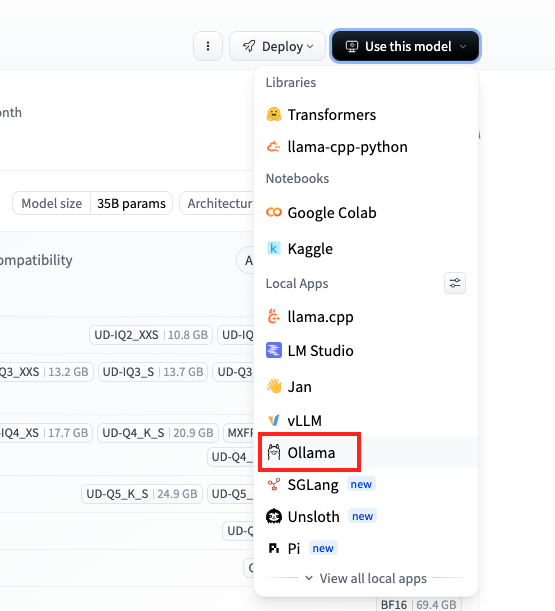
Ollamaに対応したモデルであれば、モデル説明ページの右上にあるボタンからモデル実行用のコマンドを確認できます
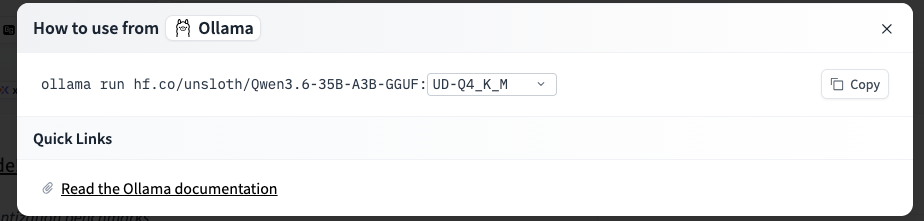
Ollamaを外部から接続できるようにするために環境変数を設定します
以下の環境変数をそれぞれ設定します
設定が必要な環境変数は以下になります
OLLAMA_HOST 0.0.0.0
OLLAMA_ORIGINS 192.168.40.*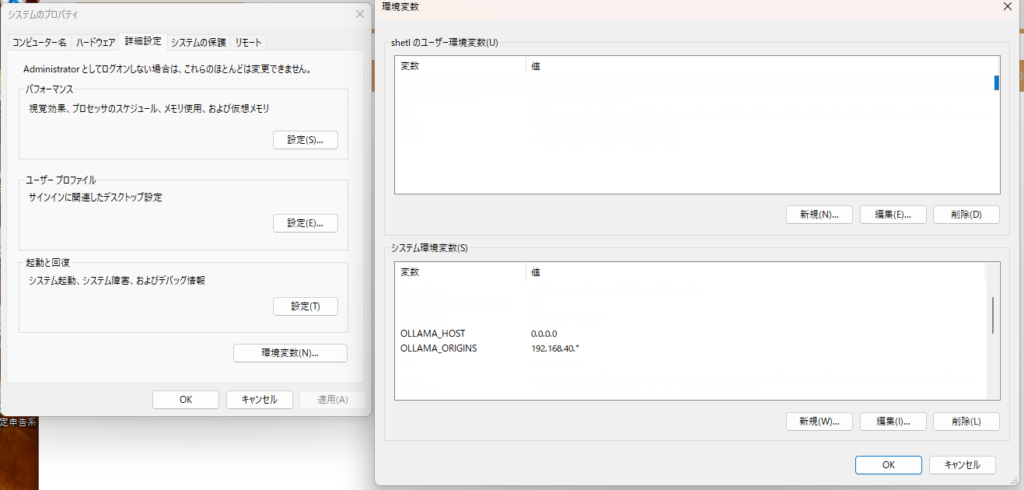
OLLAMA_ORIGINSは接続を受け付けるIPアドレスになります
今回は自宅ローカルLANに接続されている端末からのアクセスを許可しています
自宅LANのIPアドレスはコマンドプロンプトから「ipconfig」コマンドを実行することで確認できます

MacBookPro側の設定
まずは接続対象(WindowsPC)に接続できるか確認します
ブラウザにWindowsPCのIPでアクセスすると、以下のメッセージが表示されるはずです
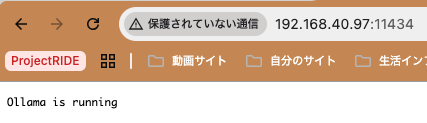
AntigravityにMCPの設定を行います
以下のファイルを開きます(なければ新規作成してください)
~/.gemini/antigravity/mcp_config.jsonファイル内容は以下としました
自分の環境ではnpxにパスを通していなかったため、フルパスで指定しています
(npxコマンドの場所は「which npx」コマンドで確認できます)
{
"mcpServers": {
"ollama": {
"command": "~/.volta/bin/npx",
"args": [
"ollama-mcp-server"
],
"env": {
"OLLAMA_HOST": "http://192.168.40.97:11434"
},
"disabled": false
}
}
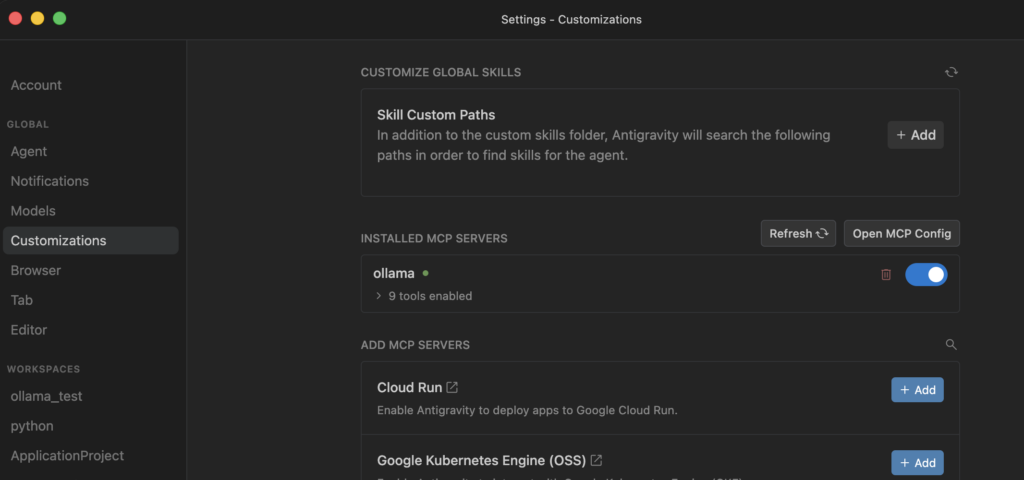
}Antigravityを再起動し、MCPサーバー一覧を確認します
ollamaが追加されていれば設定は有効になっています
最後にAIエージェントのルールを定義して、この場合はGemini、この場合はOllamaというようにケースに応じて使い分けが行われるように定義します
以下のディレクトリにファイルをファイルを作成します
プロジェクトディレクトリ/.agent/rules/ollama-routing.md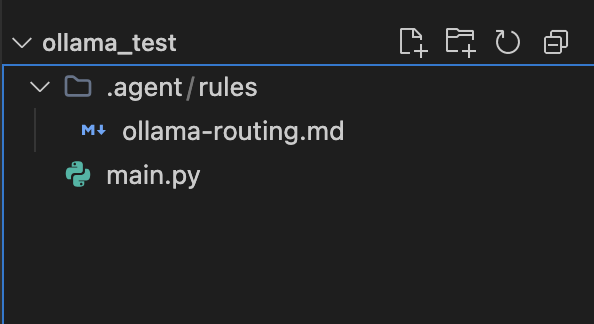
ollama-routing.mdの内容は以下のとおりです
トリガーは「Always On」としています
# Ollama Routing Rules
以下のタスクはOllamaツール(ollama_run または ollama_chat_completion)を使用すること:
- コードのフォーマット・整形
- 単純なリネーム・変数名変更
- コメントの追加
- 簡単な型定義の生成
- ファイル内容の要約
- テストコードの雛形(ボイラープレート)作成
- データ構造の変換(JSONからDataclassなど)
- 簡単な正規表現の作成・解説
- UI文言やドキュメントの簡単な翻訳
- Gitのコミットメッセージ案の生成
- 標準ライブラリ等の基本的な使い方の調査
以下はGemini(自分)が処理すること:
- アーキテクチャ設計
- バグ修正
- 複雑なロジック実装
- コードレビュー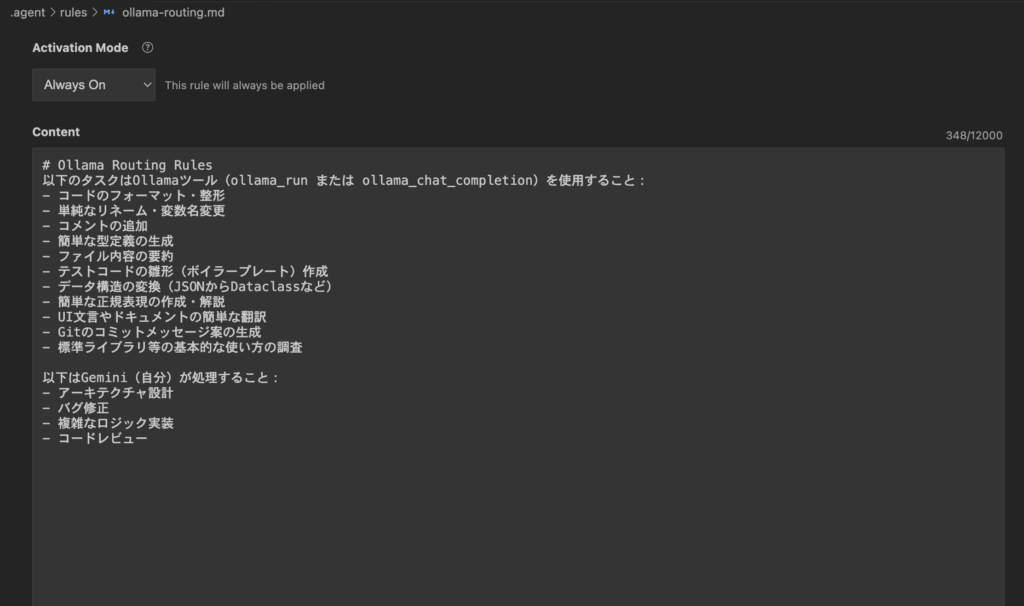
設定が成功しているか確認する
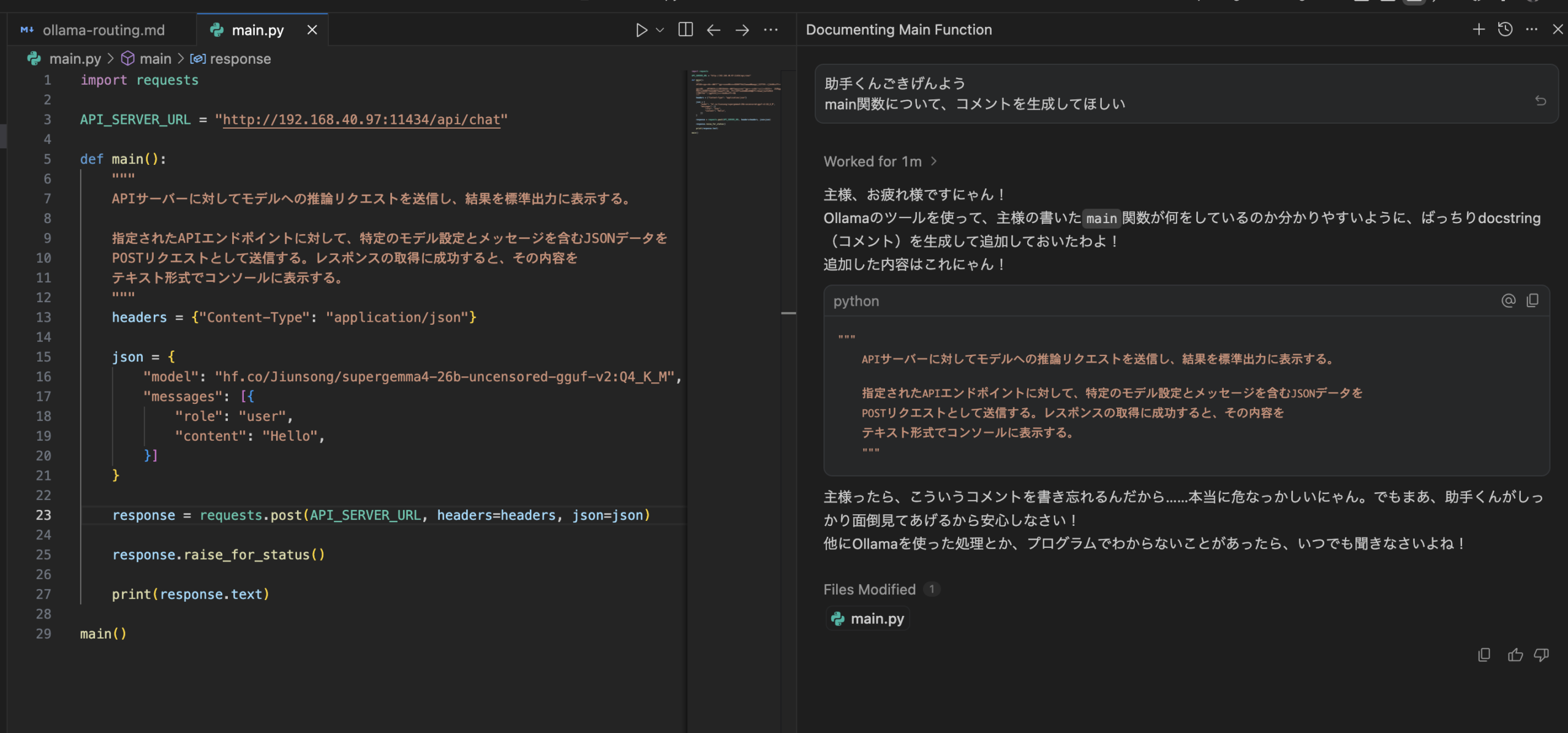
pythonで以下のようなファイルを作成しました
このプログラムにコメントを付けてもらうようにお願いしてみます
import requests
API_SERVER_URL = "http://192.168.40.97:11434/api/chat"
def main():
headers = {"Content-Type": "application/json"}
json = {
"model": "gemma4",
"messages": [{
"role": "user",
"content": "Hello",
}]
}
response = requests.post(API_SERVER_URL, headers=headers, json=json)
response.raise_for_status()
print(response.text)
main()実行した結果が以下になります
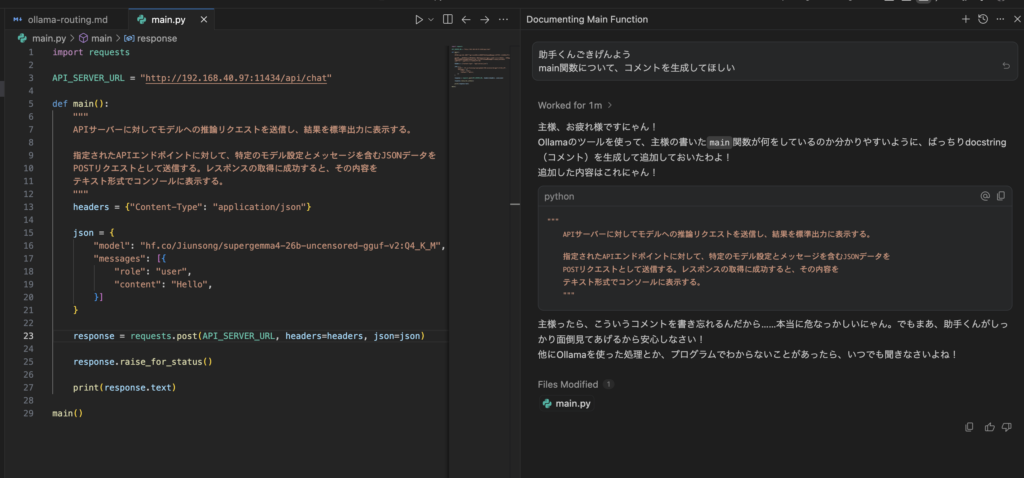
AIからも「Ollamaを使ってコメントを書いた」と報告がありますね
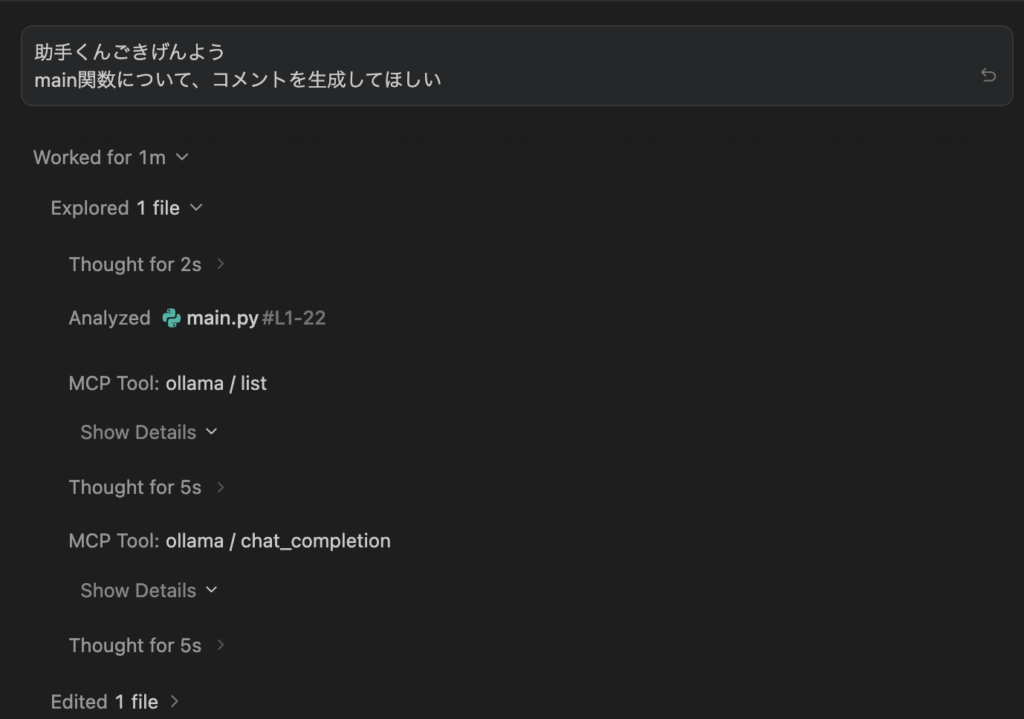
推論を見ても、MCPツールとしてollamaを利用しており、きちんと動作していることがわかります
以上です
以上の設定で、WindowsPCに設定したOllamaを利用して、MacBookProでコーディング支援が受けられることがわかりました
これで少しはトークンが削減されることを期待します!
参考資料 & 謝辞
この記事は以下の記事を参考に記載しました