GPT-2は文章の自動生成に利用できる学習モデルです。
rinna社が13億個のパラメータをもつ日本語の学習モデルを公開したことで、気軽に文章の自動生成モデルを試すことができるようになりました。
文章の自動生成は気になっていた技術の1つなので、早速試してみることにしました。
実行環境の構築
実行マシンの環境は以下のようになります
・Intel Mac
・Mac OS Monterey 12.4
condaを利用したpythonの仮想環境構築
今回はcondaを利用してpythonの仮想環境を作成しました。
仮想環境を作成しておくとアプリケーション毎に環境が分けられるため、Pythonのバージョン違いで動かなくなったり、ライブラリが競合したりといった問題を防ぐことが出来ます。
仮想環境を作成するcondaコマンドは以下のとおりです
% conda create --name gpt-2 python=3.9コマンドを実行すると、gpt-2という名前でpython3.9が導入された環境が出来ます
次にアクティベートコマンドで、環境を有効にします
% conda activate gpt-2環境が切り替わると、プロンプトの先頭に環境名が付与されます

GitからGPT-2をクローンし、必要なライブラリをインストール
GPT-2日本語モデルは以下で公開されています
https://huggingface.co/rinna/japanese-gpt2-medium
適当なディレクトリに上記リポジトリをクローンします
% git clone https://huggingface.co/rinna/japanese-gpt2-mediumクローンしたら、配下のディレクトリに移動しrequirements.txtを利用して必要なライブラリをインストールします
% cd japanese-gpt2-medium
% pip install -r requirements.txt上記コマンドを実行すると、以下のようにたくさんのライブラリがインストールされます

以上で、GPT-2モデルを動かすための環境が準備出来ました
実際にGPT-2を利用してみる
実際にGPT-2を利用してみます
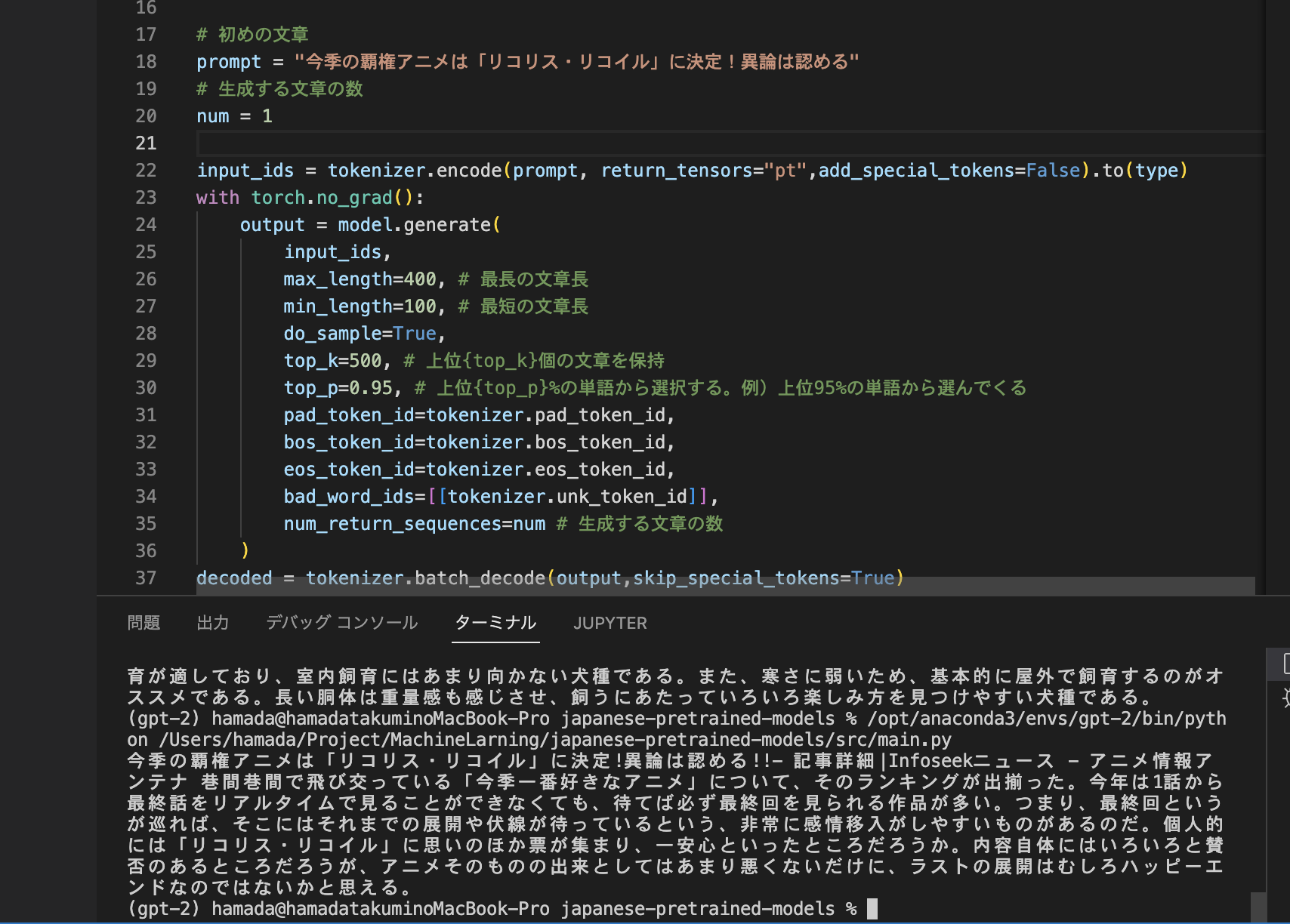
移動したディレクトリ直下にmain.pyをいうファイルを作り、以下のようなプログラムを書きました
# 参考にしたサイト
# https://www.ogis-ri.co.jp/otc/hiroba/technical/similar-document-search/part14.html
import torch
from transformers import T5Tokenizer, AutoModelForCausalLM
# トークナイザーとモデルのロード
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt-1b")
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-1b")
# GPU使用(※GPUを使用しない場合、文章生成に時間がかかります)
type = 'cpu'
if torch.cuda.is_available():
type = 'cuda'
model = model.to(type)
# 初めの文章
prompt = "シェットランドシープドックとはもふもふした毛並みが特徴の犬種である"
# 生成する文章の数
num = 1
input_ids = tokenizer.encode(prompt, return_tensors="pt",add_special_tokens=False).to(type)
with torch.no_grad():
output = model.generate(
input_ids,
max_length=400, # 最長の文章長
min_length=100, # 最短の文章長
do_sample=True,
top_k=500, # 上位{top_k}個の文章を保持
top_p=0.95, # 上位{top_p}%の単語から選択する。例)上位95%の単語から選んでくる
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
bad_word_ids=[[tokenizer.unk_token_id]],
num_return_sequences=num # 生成する文章の数
)
decoded = tokenizer.batch_decode(output,skip_special_tokens=True)
for i in range(num):
print(decoded[i])プログラム内のprompt変数に短い文章を指定してやることで、それをもとにそれらしい文章が生成されます。
実際に上記のプログラムを実行すると、以下のような文章が生成されました
シェットランドシープドックとはもふもふした毛並みが特徴の犬種である。イギリス原産であり、サイズは約20cm程度、体が大きいのも特徴である。性格は温厚で友好的であるが、飼い主には従順なタイプが多い。基本的には屋外飼育が適しており、室内飼育にはあまり向かない犬種である。また、寒さに弱いため、基本的に屋外で飼育するのがオススメである。長い胴体は重量感も感じさせ、飼うにあたっていろいろ楽しみ方を見つけやすい犬種である。
どうでしょうか? ぱっと見かなりまともな文章が生成されている印象があります。
以上です
今回はGPT-2を使ってみたというお話でした。
かなり簡単に利用できる上、生成される文章に付いてもぱっと見違和感が無いので、夏休みの日記くらいには十分利用できそうな印象です。
ファインチューニングを施せば、特定分野に特化した文章生成エンジンも作れそうなので色々応用範囲が広がりそうですね!