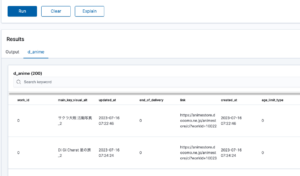
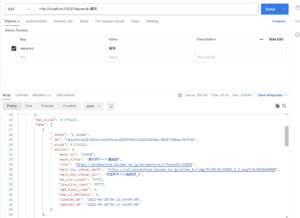
前回のエントリで形態素解析ライブラリ「kuromoji」を導入しましたので、もう少し色々と実験してみようと思います。
インデックスの定義
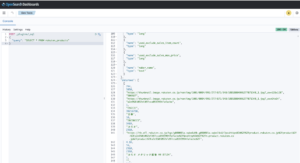
PUT test_index
{
"settings": {
"analysis": {
"analyzer": {
"kuromoji_text": {
"char_filter": [
"icu_normalizer"
],
"tokenizer": "kuromoji_tokenizer",
"filter": [
"kuromoji_baseform",
"kuromoji_part_of_speech",
"cjk_width",
"ja_stop",
"kuromoji_stemmer",
"lowercase"
]
}
}
}
},
"mappings": {
"properties": {
"test_text": {
"type": "text",
"analyzer": "kuromoji_text",
"index": true
}
}
}
}
前回の設定と比較して、「charf_ilter」「filter」が追加されています。
ちなみに、ElasticSearch公式で紹介されている設定になります。
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-kuromoji-analyzer.html
char_filterの設定
icu_normalizerを指定しました役割は記号や特殊文字をいい感じの日本語に直してくれるようです。
https://qiita.com/ikawaha/items/79fdd69c524310db065e
filterの設定
kuromoji_baseform
トークン化された活用を原型化するのに利用します。
https://blog.linkode.co.jp/entry/2020/07/20/150701#kuromoji_baseform
kuromoji_part_of_speech
不要な品詞を削除することが出来ます。
https://blog.linkode.co.jp/entry/2020/07/20/150701#kuromoji_part_of_speech
cjk_width
半角カナを全角に修正します。
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-cjk-width-tokenfilter.html
ja_stop
ストップワードの除去を行います。(ストップワードとは全文検索において検索の約荷立たない言葉「は」とか「です」のようなもの)
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-kuromoji-stop.html
kuromoji_stemmer
「ー」で終了する言葉の正規化を行います。
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-kuromoji-stemmer.html
lowercase
小文字に統一します。
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-lowercase-tokenfilter.html
以上
日本語向けのアナライザーの設定を少し詳しく見てみました。
キャラクターフィルターやフィルターを組み合わせて検索で使いやすいデータに整えていく感じでしょうかね