Antigravityのクォータ制限が厳しくなったので、ローカルLLMを利用した代替環境を構築しています
よさそうなモデルとして「Qwopus3.5-9B-Coder-MTP-GGUF:latest」というモデルを見つけたのですが、残念ながらOllamaでは動きませんでした
Qwopus3.5-9B-Coder-MTP-GGUF:latestがOllamaで動かない理由
このモデルはMTPというトークン最適化手法が用いられていますが、Ollama内臓のllama.cppのバージョンが古いようで、この最適化が施されたモデルが、まだ読み込めないとのことでした
Huggingfaceのコミュニティにも同様の投稿があり、リプライを見ると「最新のllama.cppだと動作した」とのこと
https://huggingface.co/Jackrong/Qwopus3.5-9B-Coder-MTP-GGUF/discussions/2
※MTP(Multi-Token Prediction)とは
トークンを複数まとめて予測する方法
通常のLLMは1つずつ予測→「私は」「猫が」「好き」「です」
MTPではまとめて予想→「私は」「猫が好きです」
これにより、通常のLLMと比較して2~3倍の生成速度を誇るそうです
ということで、現状MTPが使用されたモデルを利用する場合は、llama.cppを利用するのがよさそうです
llama.cppをwindowsマシンにインストールする
以前はllama.cppを利用する場合、自分でビルドを行う必要がありましたが、現在は各プラットフォームに向けたビルドが準備されているため、リリースページから環境に合わせたバイナリをダウンロードすればOKになりました
https://github.com/ggml-org/llama.cpp/releases
自分のマシンの場合、Windows + CUDA13.0の環境だったため、「Windows x64 (CUDA 13) – CUDA 13.1 DLLs」をダウンロードしました
CUDAについてはマイナーバージョンがあっていなかったため、DLLsもダウンロードしています
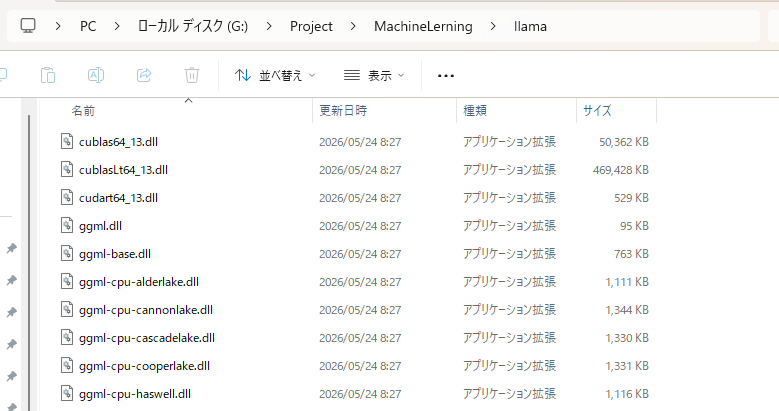
ダウンロードしたzipを展開し、適当なディレクトリに配置します
DLLsのzipは展開したら、llama.cppのディレクトリの中に配置します
自分の環境では以下のディレクトリに配置しました
llama-serverを起動し、チャットを利用してみる
バイナリの配置が終わったら、実際にターミナルから起動して動作確認を行います
自分の環境では、以下のコマンドで起動できました
※–ctx-sizeはメモリに余裕があれば大きくすることで、より多くの履歴やファイル内容を参照して回答が生成されます
cd G:\Project\MachineLerning\llama
./llama-server.exe `
-m "G:\Project\Ollama\blobs\sha256-f6fc5d193045796d9e1870cbc40f827fe55f53f70593c3f5c1968b82b9331991" `
--host 0.0.0.0 `
--port 8080 `
-ngl 999 `
--spec-type draft-mtp `
--spec-draft-n-max 2 `
--ctx-size 32768-mオプションで指定しているモデルですが、Ollamaでダウンロードしたモデルを利用したかったため、ハッシュ値になっています
Ollamaでモデルをダウンロードするとモデルのファイル名がハッシュ値になってしまうため、以下のコマンドでモデルとハッシュ値の対応を確認します
ollama show --modelfile hf.co/Jackrong/Qwopus3.5-9B-Coder-MTP-GGUF以下のような結果が出力されます
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this, replace FROM with:
# FROM hf.co/Jackrong/Qwopus3.5-9B-Coder-MTP-GGUF:latest
FROM G:\Project\Ollama\blobs\sha256-f6fc5d193045796d9e1870cbc40f827fe55f53f70593c3f5c1968b82b9331991
FROM G:\Project\Ollama\blobs\sha256-f48daca405a1c768a9514e392c3955dcc4a9d66a5cf64cf45e064092b5f20ee4
TEMPLATE """{{- $lastUserIdx := -1 -}}
{{- range $idx, $msg := .Messages -}}
{{- if eq $msg.Role "user" }}{{ $lastUserIdx = $idx }}{{ end -}}
{{- end }}
{{- if or .System .Tools }}<|im_start|>system
{{ if .System }}{{ .System }}
以下略・・・FROM以降に、ハッシュ化されたモデルのファイル名が表示されます
2つ表示されていますが、このモデルの場合、画像認識用のClip Visionが内蔵されていたため、モデルが2つ表示されたようです
今回は「sha256-f6f~」のモデルを利用します
※フォーマットが異なるモデルを指定してllama-serverを起動すると、エラーが発生するのでモデルの指定間違いに気づけます
サーバーが起動すると以下のような表記が表示されるので、ブラウザにアクセスするとチャット用のページが表示されます

http://localhost:8080 にアクセスします
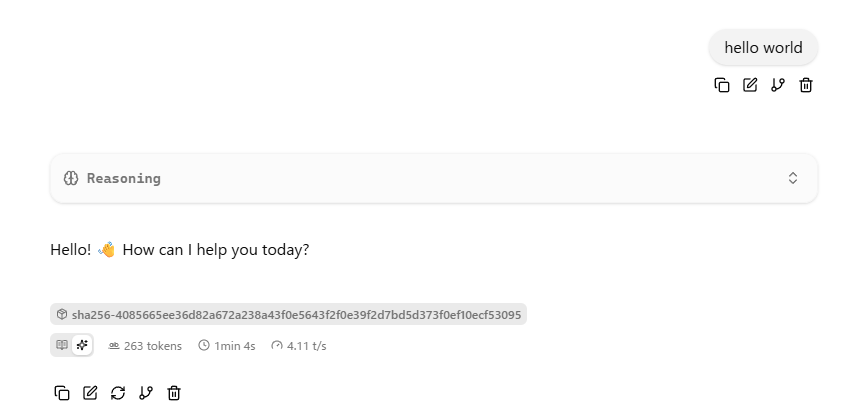
これで、llama-serverが起動し、利用可能な状態になりました
別マシンからアクセスしてみる
現在、8080ポートでサーバーが起動しているので、同一LAN内のPCからアクセスしてみます
先日MacBookにOpenCodeを利用するための環境を整えたので、その設定を変更し、llama-serverにアクセスしてみます
OpenCodeの設定内容は以下になります
{
"$schema": "https://opencode.ai/config.json",
"model": "local-llama/qwopus-coder",
"provider": {
"local-llama": {
"npm": "@ai-sdk/openai-compatible",
"name": "Local llama-server",
"options": {
"baseURL": "http://192.168.40.97:8080/v1"
},
"models": {
"qwopus-coder": {
"name": "Qwopus3.5-9B-Coder-MTP"
}
}
}
}
}modelsについては詳細に指定しなくて良い(ollamaコマンドで確認したハッシュ値でなくても良い)そうです
llama-server起動時に指定したモデルが回答に使用されるため、ここでは人間が見て分かる名前を設定します
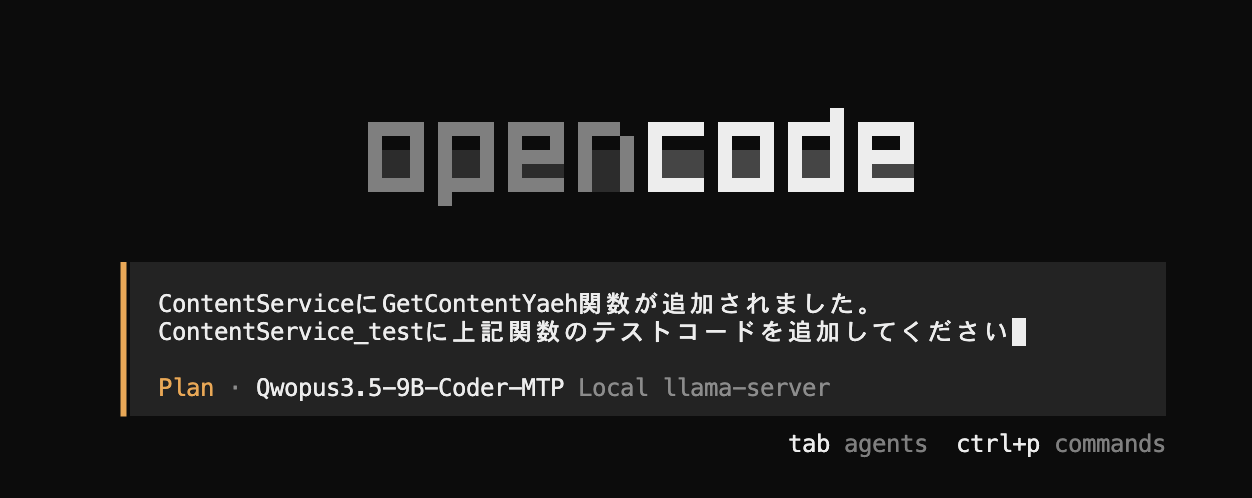
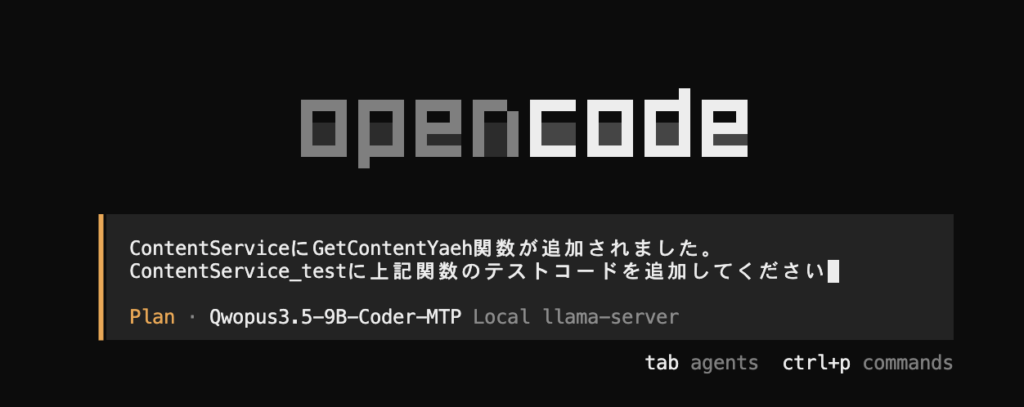
試しに、タスクを一つ振ってみました
実際に実行するとコンテキストサイズが足りなかったため、モデルの最大値である「262144」を指定してllama-serverを起動し直しています
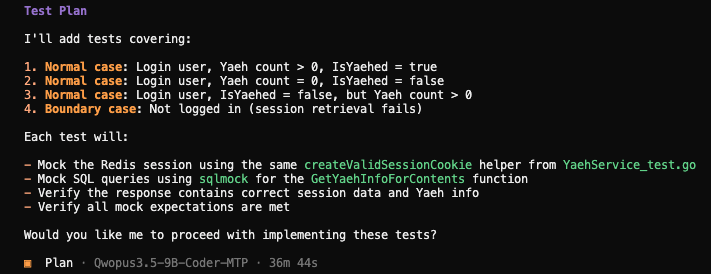
プランニングは36m44sということで、かなり時間がかかった印象です・・・
それでは、実際に実装をお願いしてみます
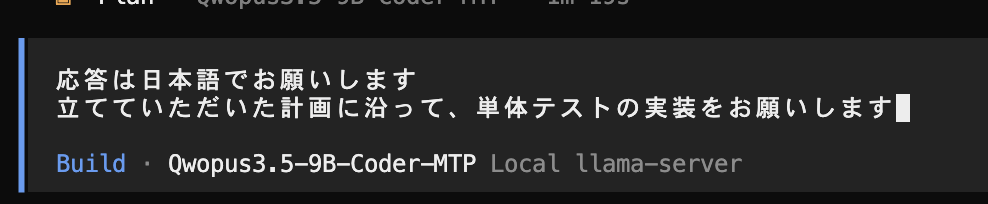
上記の結果・・・ 半日動かしても単体テストが完成しませんでした・・・
流石に時間がかかりすぎるので、マシンの限界か、起動パラメータが悪いのか、まだまだ調整が必要でした
以上
llama.cppの導入から利用するまでの紹介でした
ollamaは便利ですが、対応していないモデルもあるということで今回勉強になりました
最新のモデルを利用する場合、llama.cppをメインで利用するほうが良いかもしれませんね
今のところ、MTPモデルの動作は良好で、gemma4を利用してアシストしてもらうよりも良い結果が出ている気がします
ただ、テストコードは完成しなかったので今後使い込んでみて、どこまで利用できるのか見極めていきたいと思います