OpenSearchで日本語検索を行うために「kuromoji-tkenizer」を導入する必要があります。
今回はkuromojiを導入し、実際にどのような形態素解析が行われているのか改めて確認してみます。
参考にさせていただいた記事はこちら
https://zenn.dev/tamanugi/articles/66230d8d685dc5
日本語を格納できるインデックスを作成する
kuromojiを含んだ環境構築はDockerを利用すると簡単です
参考ページでDockerファイルの例が提示されているため、ここでは割愛させていただきます
まずはテスト用のインデックスを作成します
以下のJSONをOpenSearch Dashboardの DevToolsに貼り付けます
PUT book
{
"settings": {
"analysis": {
"analyzer": {
"kuromoji_text": {
"tokenizer": "kuromoji_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"book_title": {
"type": "text",
"analyzer": "kuromoji_text",
"index": true
}
}
}
}この状態で、一旦アナライズの状態を見てみます
(タイトルが長いラノベを利用させていただきました)
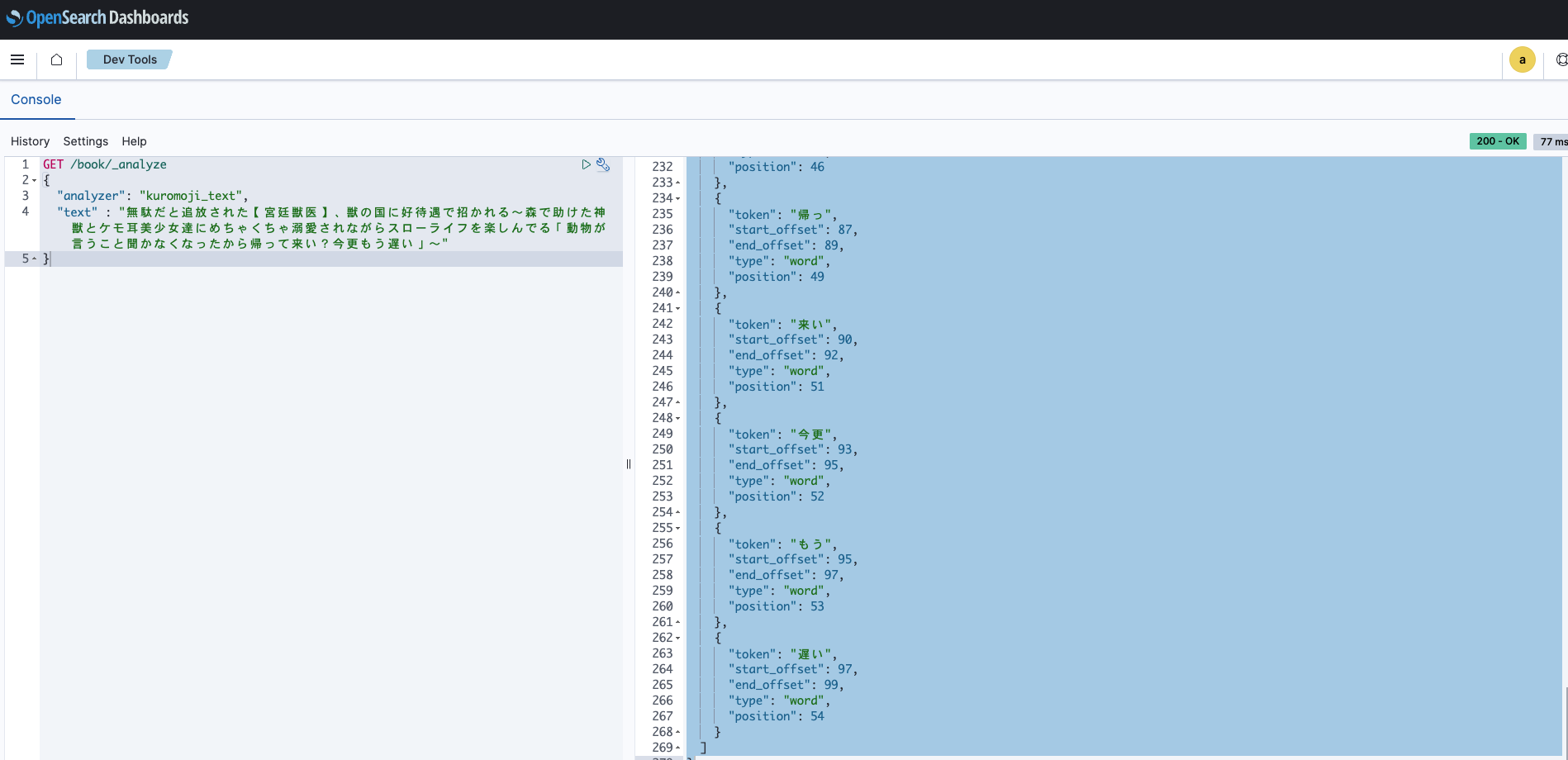
GET /book/_analyze
{
"analyzer": "kuromoji_text",
"text" : "無駄だと追放された【宮廷獣医】、獣の国に好待遇で招かれる~森で助けた神獣とケモ耳美少女達にめちゃくちゃ溺愛されながらスローライフを楽しんでる「動物が言うこと聞かなくなったから帰って来い?今更もう遅い」~"
}結果は以下の通り
{
"tokens": [
{
"token": "無駄",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "だ",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1
},
{
"token": "と",
"start_offset": 3,
"end_offset": 4,
"type": "word",
"position": 2
},
{
"token": "追放",
"start_offset": 4,
"end_offset": 6,
"type": "word",
"position": 3
},
{
"token": "さ",
"start_offset": 6,
"end_offset": 7,
"type": "word",
"position": 4
},
{
"token": "れ",
"start_offset": 7,
"end_offset": 8,
"type": "word",
"position": 5
},
{
"token": "た",
"start_offset": 8,
"end_offset": 9,
"type": "word",
"position": 6
},
{
"token": "宮廷",
"start_offset": 10,
"end_offset": 12,
"type": "word",
"position": 7
},
{
"token": "獣医",
"start_offset": 12,
"end_offset": 14,
"type": "word",
"position": 8
},
{
"token": "獣",
"start_offset": 16,
"end_offset": 17,
"type": "word",
"position": 9
},
{
"token": "の",
"start_offset": 17,
"end_offset": 18,
"type": "word",
"position": 10
},
{
"token": "国",
"start_offset": 18,
"end_offset": 19,
"type": "word",
"position": 11
},
{
"token": "に",
"start_offset": 19,
"end_offset": 20,
"type": "word",
"position": 12
},
{
"token": "好",
"start_offset": 20,
"end_offset": 21,
"type": "word",
"position": 13
},
{
"token": "待遇",
"start_offset": 21,
"end_offset": 23,
"type": "word",
"position": 14
},
{
"token": "で",
"start_offset": 23,
"end_offset": 24,
"type": "word",
"position": 15
},
{
"token": "招か",
"start_offset": 24,
"end_offset": 26,
"type": "word",
"position": 16
},
{
"token": "れる",
"start_offset": 26,
"end_offset": 28,
"type": "word",
"position": 17
},
{
"token": "森",
"start_offset": 29,
"end_offset": 30,
"type": "word",
"position": 18
},
{
"token": "で",
"start_offset": 30,
"end_offset": 31,
"type": "word",
"position": 19
},
{
"token": "助け",
"start_offset": 31,
"end_offset": 33,
"type": "word",
"position": 20
},
{
"token": "た",
"start_offset": 33,
"end_offset": 34,
"type": "word",
"position": 21
},
{
"token": "神",
"start_offset": 34,
"end_offset": 35,
"type": "word",
"position": 22
},
{
"token": "獣",
"start_offset": 35,
"end_offset": 36,
"type": "word",
"position": 23
},
{
"token": "と",
"start_offset": 36,
"end_offset": 37,
"type": "word",
"position": 24
},
{
"token": "ケモ",
"start_offset": 37,
"end_offset": 39,
"type": "word",
"position": 25
},
{
"token": "耳",
"start_offset": 39,
"end_offset": 40,
"type": "word",
"position": 26
},
{
"token": "美少女",
"start_offset": 40,
"end_offset": 43,
"type": "word",
"position": 27
},
{
"token": "達",
"start_offset": 43,
"end_offset": 44,
"type": "word",
"position": 28
},
{
"token": "に",
"start_offset": 44,
"end_offset": 45,
"type": "word",
"position": 29
},
{
"token": "めちゃくちゃ",
"start_offset": 45,
"end_offset": 51,
"type": "word",
"position": 30
},
{
"token": "溺愛",
"start_offset": 51,
"end_offset": 53,
"type": "word",
"position": 31
},
{
"token": "さ",
"start_offset": 53,
"end_offset": 54,
"type": "word",
"position": 32
},
{
"token": "れ",
"start_offset": 54,
"end_offset": 55,
"type": "word",
"position": 33
},
{
"token": "ながら",
"start_offset": 55,
"end_offset": 58,
"type": "word",
"position": 34
},
{
"token": "スロー",
"start_offset": 58,
"end_offset": 61,
"type": "word",
"position": 35
},
{
"token": "ライフ",
"start_offset": 61,
"end_offset": 64,
"type": "word",
"position": 36
},
{
"token": "を",
"start_offset": 64,
"end_offset": 65,
"type": "word",
"position": 37
},
{
"token": "楽しん",
"start_offset": 65,
"end_offset": 68,
"type": "word",
"position": 38
},
{
"token": "でる",
"start_offset": 68,
"end_offset": 70,
"type": "word",
"position": 39
},
{
"token": "動物",
"start_offset": 71,
"end_offset": 73,
"type": "word",
"position": 40
},
{
"token": "が",
"start_offset": 73,
"end_offset": 74,
"type": "word",
"position": 41
},
{
"token": "言う",
"start_offset": 74,
"end_offset": 76,
"type": "word",
"position": 42
},
{
"token": "こと",
"start_offset": 76,
"end_offset": 78,
"type": "word",
"position": 43
},
{
"token": "聞か",
"start_offset": 78,
"end_offset": 80,
"type": "word",
"position": 44
},
{
"token": "なく",
"start_offset": 80,
"end_offset": 82,
"type": "word",
"position": 45
},
{
"token": "なっ",
"start_offset": 82,
"end_offset": 84,
"type": "word",
"position": 46
},
{
"token": "た",
"start_offset": 84,
"end_offset": 85,
"type": "word",
"position": 47
},
{
"token": "から",
"start_offset": 85,
"end_offset": 87,
"type": "word",
"position": 48
},
{
"token": "帰っ",
"start_offset": 87,
"end_offset": 89,
"type": "word",
"position": 49
},
{
"token": "て",
"start_offset": 89,
"end_offset": 90,
"type": "word",
"position": 50
},
{
"token": "来い",
"start_offset": 90,
"end_offset": 92,
"type": "word",
"position": 51
},
{
"token": "今更",
"start_offset": 93,
"end_offset": 95,
"type": "word",
"position": 52
},
{
"token": "もう",
"start_offset": 95,
"end_offset": 97,
"type": "word",
"position": 53
},
{
"token": "遅い",
"start_offset": 97,
"end_offset": 99,
"type": "word",
"position": 54
}
]
}かなり細切れに分析されたようです
特に一文字のインデックスは不要なため、kuromoji_part_of_speechを追加して除去してみます
試したところ、settingsは一旦インデックスを削除しないと変更できないようなので、一旦bookインデックスを削除し、以下の設定で再作成します
PUT book
{
"settings": {
"analysis": {
"analyzer": {
"kuromoji_text": {
"tokenizer": "kuromoji_tokenizer",
"filter": ["kuromoji_part_of_speech"]
}
}
}
},
"mappings": {
"properties": {
"book_title": {
"type": "text",
"analyzer": "kuromoji_text",
"index": true
}
}
}
}この状態でもう一度ラノベのタイトルを分析させてみます
結果は以下の通り
{
"tokens": [
{
"token": "無駄",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "追放",
"start_offset": 4,
"end_offset": 6,
"type": "word",
"position": 3
},
{
"token": "さ",
"start_offset": 6,
"end_offset": 7,
"type": "word",
"position": 4
},
{
"token": "れ",
"start_offset": 7,
"end_offset": 8,
"type": "word",
"position": 5
},
{
"token": "宮廷",
"start_offset": 10,
"end_offset": 12,
"type": "word",
"position": 7
},
{
"token": "獣医",
"start_offset": 12,
"end_offset": 14,
"type": "word",
"position": 8
},
{
"token": "獣",
"start_offset": 16,
"end_offset": 17,
"type": "word",
"position": 9
},
{
"token": "国",
"start_offset": 18,
"end_offset": 19,
"type": "word",
"position": 11
},
{
"token": "好",
"start_offset": 20,
"end_offset": 21,
"type": "word",
"position": 13
},
{
"token": "待遇",
"start_offset": 21,
"end_offset": 23,
"type": "word",
"position": 14
},
{
"token": "招か",
"start_offset": 24,
"end_offset": 26,
"type": "word",
"position": 16
},
{
"token": "れる",
"start_offset": 26,
"end_offset": 28,
"type": "word",
"position": 17
},
{
"token": "森",
"start_offset": 29,
"end_offset": 30,
"type": "word",
"position": 18
},
{
"token": "助け",
"start_offset": 31,
"end_offset": 33,
"type": "word",
"position": 20
},
{
"token": "神",
"start_offset": 34,
"end_offset": 35,
"type": "word",
"position": 22
},
{
"token": "獣",
"start_offset": 35,
"end_offset": 36,
"type": "word",
"position": 23
},
{
"token": "ケモ",
"start_offset": 37,
"end_offset": 39,
"type": "word",
"position": 25
},
{
"token": "耳",
"start_offset": 39,
"end_offset": 40,
"type": "word",
"position": 26
},
{
"token": "美少女",
"start_offset": 40,
"end_offset": 43,
"type": "word",
"position": 27
},
{
"token": "達",
"start_offset": 43,
"end_offset": 44,
"type": "word",
"position": 28
},
{
"token": "めちゃくちゃ",
"start_offset": 45,
"end_offset": 51,
"type": "word",
"position": 30
},
{
"token": "溺愛",
"start_offset": 51,
"end_offset": 53,
"type": "word",
"position": 31
},
{
"token": "さ",
"start_offset": 53,
"end_offset": 54,
"type": "word",
"position": 32
},
{
"token": "れ",
"start_offset": 54,
"end_offset": 55,
"type": "word",
"position": 33
},
{
"token": "スロー",
"start_offset": 58,
"end_offset": 61,
"type": "word",
"position": 35
},
{
"token": "ライフ",
"start_offset": 61,
"end_offset": 64,
"type": "word",
"position": 36
},
{
"token": "楽しん",
"start_offset": 65,
"end_offset": 68,
"type": "word",
"position": 38
},
{
"token": "でる",
"start_offset": 68,
"end_offset": 70,
"type": "word",
"position": 39
},
{
"token": "動物",
"start_offset": 71,
"end_offset": 73,
"type": "word",
"position": 40
},
{
"token": "言う",
"start_offset": 74,
"end_offset": 76,
"type": "word",
"position": 42
},
{
"token": "こと",
"start_offset": 76,
"end_offset": 78,
"type": "word",
"position": 43
},
{
"token": "聞か",
"start_offset": 78,
"end_offset": 80,
"type": "word",
"position": 44
},
{
"token": "なっ",
"start_offset": 82,
"end_offset": 84,
"type": "word",
"position": 46
},
{
"token": "帰っ",
"start_offset": 87,
"end_offset": 89,
"type": "word",
"position": 49
},
{
"token": "来い",
"start_offset": 90,
"end_offset": 92,
"type": "word",
"position": 51
},
{
"token": "今更",
"start_offset": 93,
"end_offset": 95,
"type": "word",
"position": 52
},
{
"token": "もう",
"start_offset": 95,
"end_offset": 97,
"type": "word",
"position": 53
},
{
"token": "遅い",
"start_offset": 97,
"end_offset": 99,
"type": "word",
"position": 54
}
]
}一部のトークンが削除されてます(動物が言うこと聞かないの「が」の部分など)
これで検索ノイズになりそうなトークンがひとまず削除できましたが、日本語検索を行うためにはまだまだ調整の余地がありそうです。
次回以降はもう少し日本語の調整について調べて見たいと思います

created by Rinker
¥3,300
(2026/07/24 19:38:58時点 楽天市場調べ-詳細)