ElasticSearchを対象にした記事ですが、ZOZOTownの技術ブログで日本語検索を扱う設定が公開されていました
https://techblog.zozo.com/entry/elasticsearch-mapping-config-for-japanese-search
kuromojiプラグイン機能を確認する
kuromojiの機能は以下から確認できます
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-kuromoji-analyzer.html
kuromoji紹介ページに既に日本語を扱うためのサンプルが紹介されていました
PUT books
{
"settings": {
"analysis": {
"analyzer": {
"kuromoji_text": {
"type": "custom",
"char_filter":[
"icu_normalizer"
],
"tokenizer": "kuromoji_tokenizer",
"filter": [
"kuromoji_baseform",
"kuromoji_part_of_speech",
"ja_stop",
"kuromoji_number",
"kuromoji_stemmer"
]
}
}
}
},
"mappings": {
"properties": {
"book_title": {
"type": "text",
"analyzer": "kuromoji_text",
"index": true
}
}
}
}キャラクターフィルター、トークンフィルターでそれぞれどのような処理が行われているかはZOZOTownブログにまとまっているのでそちらを御覧ください(丸投げ)
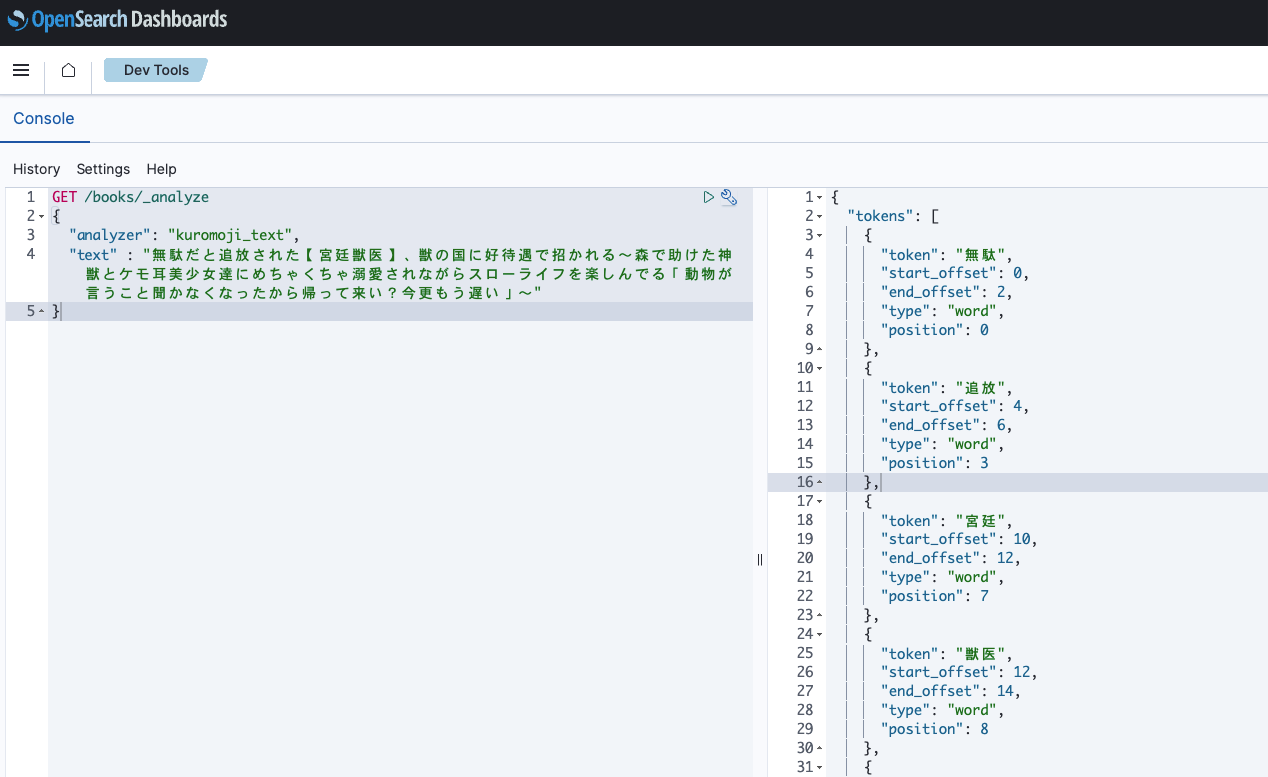
上記トークナイザーを設定し、前回利用した最も長いラノベのタイトルを解析させてみます
解析させてみる
解析させるのは前回試した最も長いラノベのタイトルです
GET /books/_analyze
{
"analyzer": "kuromoji_text",
"text" : "無駄だと追放された【宮廷獣医】、獣の国に好待遇で招かれる~森で助けた神獣とケモ耳美少女達にめちゃくちゃ溺愛されながらスローライフを楽しんでる「動物が言うこと聞かなくなったから帰って来い?今更もう遅い」~"
}結果は以下になります
{
"tokens": [
{
"token": "無駄",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "追放",
"start_offset": 4,
"end_offset": 6,
"type": "word",
"position": 3
},
{
"token": "宮廷",
"start_offset": 10,
"end_offset": 12,
"type": "word",
"position": 7
},
{
"token": "獣医",
"start_offset": 12,
"end_offset": 14,
"type": "word",
"position": 8
},
{
"token": "獣",
"start_offset": 16,
"end_offset": 17,
"type": "word",
"position": 9
},
{
"token": "国",
"start_offset": 18,
"end_offset": 19,
"type": "word",
"position": 11
},
{
"token": "好",
"start_offset": 20,
"end_offset": 21,
"type": "word",
"position": 13
},
{
"token": "待遇",
"start_offset": 21,
"end_offset": 23,
"type": "word",
"position": 14
},
{
"token": "招く",
"start_offset": 24,
"end_offset": 26,
"type": "word",
"position": 16
},
{
"token": "森",
"start_offset": 29,
"end_offset": 30,
"type": "word",
"position": 18
},
{
"token": "助ける",
"start_offset": 31,
"end_offset": 33,
"type": "word",
"position": 20
},
{
"token": "神",
"start_offset": 34,
"end_offset": 35,
"type": "word",
"position": 22
},
{
"token": "獣",
"start_offset": 35,
"end_offset": 36,
"type": "word",
"position": 23
},
{
"token": "ケモ",
"start_offset": 37,
"end_offset": 39,
"type": "word",
"position": 25
},
{
"token": "耳",
"start_offset": 39,
"end_offset": 40,
"type": "word",
"position": 26
},
{
"token": "美少女",
"start_offset": 40,
"end_offset": 43,
"type": "word",
"position": 27
},
{
"token": "達",
"start_offset": 43,
"end_offset": 44,
"type": "word",
"position": 28
},
{
"token": "めちゃくちゃ",
"start_offset": 45,
"end_offset": 51,
"type": "word",
"position": 30
},
{
"token": "溺愛",
"start_offset": 51,
"end_offset": 53,
"type": "word",
"position": 31
},
{
"token": "スロー",
"start_offset": 58,
"end_offset": 61,
"type": "word",
"position": 35
},
{
"token": "ライフ",
"start_offset": 61,
"end_offset": 64,
"type": "word",
"position": 36
},
{
"token": "楽しむ",
"start_offset": 65,
"end_offset": 68,
"type": "word",
"position": 38
},
{
"token": "でる",
"start_offset": 68,
"end_offset": 70,
"type": "word",
"position": 39
},
{
"token": "動物",
"start_offset": 71,
"end_offset": 73,
"type": "word",
"position": 40
},
{
"token": "言う",
"start_offset": 74,
"end_offset": 76,
"type": "word",
"position": 42
},
{
"token": "聞く",
"start_offset": 78,
"end_offset": 80,
"type": "word",
"position": 44
},
{
"token": "帰る",
"start_offset": 87,
"end_offset": 89,
"type": "word",
"position": 49
},
{
"token": "来る",
"start_offset": 90,
"end_offset": 92,
"type": "word",
"position": 51
},
{
"token": "今更",
"start_offset": 93,
"end_offset": 95,
"type": "word",
"position": 52
},
{
"token": "もう",
"start_offset": 95,
"end_offset": 97,
"type": "word",
"position": 53
},
{
"token": "遅い",
"start_offset": 97,
"end_offset": 99,
"type": "word",
"position": 54
}
]
}前回の記事と比較して、かなりトークンが整理された印象です
以上
ということで、日本語形態素解析についてZOZOTownと公式のサンプルを試してみたお話でした
実際には更にここから検索するデータに合ったトークンが生成されるようにチューニングを行う必要があるかと思います
次はユーザー辞書反映か、もう一つの形態素解析であるsudachiも試してみたいところです
あとはElasticSearchの情報もOpenSearchに流用できるのもありがたいですね
すべての情報でElasticSearch == OpenSearchにはならないと思いますが、ElasticSearchの設定もOpenSearchで利用できるのか試してみる価値はありそうです